Spark Listener, and how to setup yours [3AE]
The product manager, the senior developer, the team lead in a smaller company will always worry about 2 things in every initiative they take:
How much cost does it save?
How much faster can it be?
WHY IS THERE A 3rd ITEM IN A LIST OF 2 THINGS
So do you also worry about the same problems? Like Jay-Z said:

You don’t solve such problems from top-down. You solve them from the bottom-up. You see when you work closely with building and maintaining big data systems, and get your hands dirty every day of every week, you get an unfair advantage which many people won’t.
“You can always find the truth behind whether or not something is possible on the ground level?”
The Setup
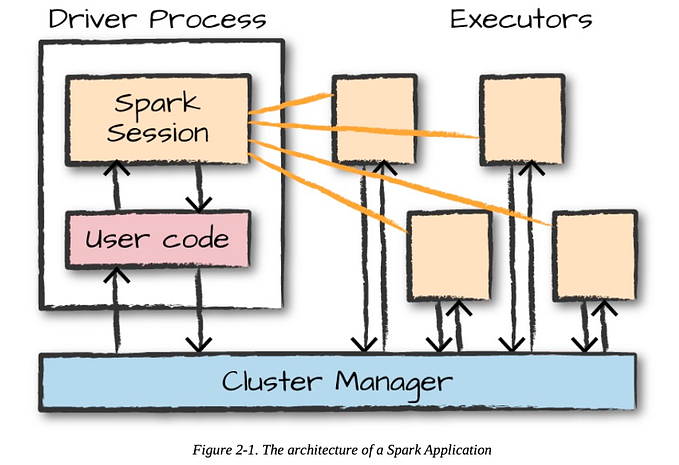
In this 3AE [3 Act Engineering], we’ll discuss about Spark Listener (ref: here), which is a simple yet effective way to listen to events the spark scheduler emits right from the moment you submit the application until it ends.
The Spark UI is pretty great, no doubt about it. But, sometimes, you might want to store certain details in a specific way so that you can worry about them later instead of keeping the browser open for days.
Besides, the only good thing about data engineering as a whole, is the capability to generate MORE DATA.
For our project, we’ll try overriding the following and see what can we get out of them.
onApplicationStart, or when the application starts (invoked only once)
onJobStart, or when one job within the application starts (invoked multiple times)
onStageCompleted, or when a stage within the job is completed (invoked multiple times)
onTaskEnd, or when a task ends (invoked multiple times)
onApplicationEnd, or when the application ends (invoked only once)
Lets start from the start then.
You buy a laptop
You get rid of the previously installed Windows OS (because that isn’t cool, even with the WSL)
You install whatever version of Linux that goes with your hoodie color and then install the following: Java, Spark, sbt, an IDE with dark theme
Finally you crunch your fingers the way they’re shown below and you’re good to go.

If everything looks good, you should check the versions of everything installed so far and it should look similar to something like this:



There’s absolutely no point in reading further, until you’ve ensured all of these are installed and are in working conditions.
Why?
Because this ain’t no 🐍 that we’ve been swimming deep in till today, without the fear of compilation errors.

Let’s start by creating a empty scala project
sbt new scala/scala3.g8With the name: “my-spark-listener”, you should be good to go.
The tree my-spark-listener should give the following output:

Next, let’s create/update the content of the following files, before jumping into the dreaded Scala territory.
project/build.properties
sbt.version=1.5.5project/assembly.sbt
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.15.0")build.sbt
lazy val root = (project in file("."))
.settings(
name := "my-spark-listener",
version := "0.1",
scalaVersion := "2.12.18",
assemblyJarName in assembly := "my-spark-listener.jar",
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "3.1.2" % Provided,
"org.apache.spark" %% "spark-sql" % "3.1.2" % Provided
)
)
assemblyMergeStrategy in assembly := {
case PathList("META-INF", _*) => MergeStrategy.discard
case _ => MergeStrategy.first
}And that’s all for the section. Up next, we’ll try our best to simply copy-paste from the article to avoid any compilation errors.
The Build
There are 2 important files we need to worry about (among other things in life, but let’s not get ahead of ourselves)
The spark listener class
The spark job
For the first one, let’s go ahead and create it in the following location:
src/main/scala/com/main/listenerclass/MediumSparkListener.scala
package com.main.listenerclass
import org.apache.spark.scheduler._
import org.apache.spark.sql.SparkSession
import java.io.{File, PrintWriter}
import java.text.SimpleDateFormat
import java.util.Date
class MediumSparkListener extends SparkListener {
var writer: PrintWriter = _
val dateFormat = new SimpleDateFormat("yyyy-MM-dd_HH-mm-ss")
val timestamp = dateFormat.format(new Date())
val fileName = s"spark_metrics_$timestamp.txt"
writer = new PrintWriter(new File(fileName))
override def onJobStart(jobStart: SparkListenerJobStart): Unit = {
val timestamp = dateFormat.format(new Date(jobStart.time))
writer.println(s"Job ${jobStart.jobId} started at $timestamp with ${jobStart.stageInfos.length} stages.")
}
override def onJobEnd(jobEnd: SparkListenerJobEnd): Unit = {
val timestamp = dateFormat.format(new Date())
writer.println(s"Job ${jobEnd.jobId} ended at $timestamp with result: ${jobEnd.jobResult}.")
writer.println("----------")
}
override def onApplicationEnd(applicationEnd: SparkListenerApplicationEnd): Unit = {
writer.close()
}
}For the second one, let’s keep things light and write a very simple spark job:
src/main/scala/MySparkJob.scala
import org.apache.spark.sql.SparkSession
object MySparkJob {
def main(args: Array[String]) {
val inputPath = args(0)
val spark = SparkSession.builder().appName("my_spark_job").getOrCreate()
val df = spark.read.format("csv").option("header", "true").load(inputPath)
df.createOrReplaceTempView("temp_table")
spark.sql("SELECT count(*) as total_rows FROM temp_table group by col1").show()
spark.stop()
}
}data.csv
col1,col2
1,A
2,B
1,C
2,D
3,E
3,F
3,G
4,H
Let’s do a speed-run on what did we did do so far:
Initialize a Scala project.
Define all the dependencies for it.
Wrote the core logic for the spark listener class, one that does the following: print the timestamp when a job starts, the number of stages it had, the timestamp when the job ends, as well as its state.
Wrote a simple spark application which: reads a csv file, runs a SQL query against it and then displays the result.
A sample CSV file to run the spark application against.
The next step is probably the most important, and its the same as the title of the section:
— — — — —THE BUILD — — — — —
Ensure you’re at the right location (my-spark-listener) and then, let’s try this out:
sbt assemblyAfter a few seconds of the gears whirring, should see something like this below:

On doing an ls target/scala-2.12 , you should see the following, which basically means we were able to build the jar without any major issue:

The Payoff
The moment has arrived, to run a really long spark-submit command, and see where did the things go wrong.
spark-submit --conf "spark.extraListeners=com.main.listenerclass.MediumSparkListener" --class MySparkJob target/scala-2.12/spark-custom-query-listener.jar ./data.csvIf the stars were aligned in the first go, ls should give something that looks similar to:

Lets go ahead and add more to the listener class to really extract as much information as possible.
With some enhancements, MediumSparkListener should look like this:
src/main/scala/com/main/listenerclass/MediumSparkListener.scala
package com.main.listenerclass
import org.apache.spark.scheduler._
import org.apache.spark.sql.SparkSession
import java.io.{File, PrintWriter}
import java.text.SimpleDateFormat
import java.util.Date
class MediumSparkListener extends SparkListener {
var writer: PrintWriter = _
val dateFormat = new SimpleDateFormat("yyyy-MM-dd_HH-mm-ss")
val timestamp = dateFormat.format(new Date())
val fileName = s"spark_metrics_$timestamp.txt"
writer = new PrintWriter(new File(fileName))
override def onJobStart(jobStart: SparkListenerJobStart): Unit = {
val timestamp = dateFormat.format(new Date(jobStart.time))
writer.println(s"Job ${jobStart.jobId} started at $timestamp with ${jobStart.stageInfos.length} stages.")
}
override def onJobEnd(jobEnd: SparkListenerJobEnd): Unit = {
val timestamp = dateFormat.format(new Date())
writer.println(s"Job ${jobEnd.jobId} ended at $timestamp with result: ${jobEnd.jobResult}.")
writer.println("----------")
}
override def onStageCompleted(stageCompleted: SparkListenerStageCompleted): Unit = {
val stageInfo = stageCompleted.stageInfo
writer.println(s"Stage ${stageInfo.stageId} (${stageInfo.name}) completed with ${stageInfo.numTasks} tasks.")
val stageMetrics = stageInfo.taskMetrics
writer.println(s"Stage Metrics: Executor run time: ${stageMetrics.executorRunTime} ms, " +
s"Shuffle Read: ${stageMetrics.shuffleReadMetrics.totalBytesRead} bytes, " +
s"Shuffle Write: ${stageMetrics.shuffleWriteMetrics.bytesWritten} bytes")
writer.println("----------")
}
override def onTaskEnd(taskEnd: SparkListenerTaskEnd): Unit = {
val metrics = taskEnd.taskMetrics
writer.println(s"Task ${taskEnd.taskInfo.taskId} in stage ${taskEnd.stageId} ended.")
writer.println(s"Executor run time: ${metrics.executorRunTime} ms")
writer.println(s"Input Metrics: ${if (metrics.inputMetrics != null) metrics.inputMetrics.bytesRead + " bytes" else "No input"}")
writer.println(s"Output Metrics: ${if (metrics.outputMetrics != null) metrics.outputMetrics.bytesWritten + " bytes" else "No output"}")
writer.println(s"Shuffle Read Metrics: ${metrics.shuffleReadMetrics.totalBytesRead} bytes read")
writer.println(s"Shuffle Write Metrics: ${metrics.shuffleWriteMetrics.bytesWritten} bytes written")
writer.println("----------")
}
override def onApplicationEnd(applicationEnd: SparkListenerApplicationEnd): Unit = {
writer.close()
}
}Also, let’s add more to our spark application to really see how far the listener can do the listening.
src/main/scala/MySparkJob.scala
import org.apache.spark.sql.SparkSession
object MySparkJob {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("My Spark Job").getOrCreate()
val data = Seq(("Alice", 34), ("Bob", 45), ("Cathy", 29), ("David", 56))
val df = spark.createDataFrame(data).toDF("Name", "Age")
df.write.mode("overwrite").parquet("data/output")
val readDf = spark.read.parquet("data/output")
val filteredDf = readDf.filter("Age > 30")
val groupedDf = filteredDf.groupBy("Age").count()
groupedDf.show()
val sortedDf = filteredDf.sort("Name")
sortedDf.show()
spark.stop()
}
}Once again, running this end to end after the build. Follow the below commands to do this:
sbt assembly
spark-submit --conf "spark.extraListeners=com.main.listenerclass.MediumSparkListener" --class MySparkJob target/scala-2.12/spark-custom-query-listener.jarThe shell should be filled up with a lot of black & white lines of code. With one of the final output looking like this:

Additionally, the ls command would give you another file containing metrics from this run:

And voila!, we are so done with this.
Both the files created so far will have some interesting insights, including but not limited to:
- In a spark application, when did a job start, and with how many stages
- When did that job end
- What tasks were there for the job
- How much time did each task take
- For each task, what amount of bytes were considered as input, as output, were in shuffle read and in shuffle write
- AND MANY MORE…

Is this information overload???
Maybe. So, why use spark-listener at all? I might not have a very convincing case if they seem overwhelming to you (as they did to me for a good amount of time), but following are some of the use-cases you might want to use this for:
“You’re interested in custom metrics collection and storing them in a separate table to keep track of how long an application runs, how much time each job took etc.”
“If a stage or a job takes too long, you want to trigger certain alerts as something might have gone down wrong.”
“You want to collect detailed profiling information to build patterns upon what jobs are pretty optimal and what aren’t.”
Station Eleven was the show of the month, which sits right alongside the rest of the epic but ended-too-soon SciFi dramas like:
The OA, The Leftovers and Tales from the loop
Out of Challengers and Dream Scenario, I am not sure which one to recommend more. But definitely, watching both will make you have a lot of

Also, I finally moved to something which is “ANC”. Just feels good to share,

Until the next one, fin!

![Apache Arrow, making Spark even faster [3AE]](https://miro.medium.com/v2/resize:fit:679/1*7ukrOexLk8MLCRxr-vBL4w.png)
![Kafka with Python: Part 2 [3AE]](https://miro.medium.com/v2/resize:fit:679/0*5sqzUO2WkpU0L_-r.jpg)
![Building a distributed framework in Go - 1 [3AE]](https://miro.medium.com/v2/resize:fit:679/1*KjiuGSgvnZIdas1I5lekGg.png)