Kafka with Python: Part 1 [3AE]
Streaming with some pythonic swag
So, its me. Again.
After months of silence, I’ve decided to give this passion for writing another try, with hope to write at least 5 articles by the end of the year (yeah, that’s gonna fail miserably). Now I know it feels unachievable, but that’s just everything else in life as well. Alright, enough depressing jokes, lets get started.
I’ve spent most of my time as a Data Engineer working and maintaining batch data pipelines. Now, they are fun to work with, but they aren’t the only data pipelines that exist. There’s a sibling to batch which is probably more fun to work with, and yes, you know it as:

You can also click here for Part-2 to jump to the code part directly.
Working with streaming is a different type of thrill. Imagine someone buying chocolates in a store, and the second it gets into the system as a transaction record, you have it within your stream. All in real time, like, in real-real. No matter how many such chocolates are bought every second in this world, the second they are bought, you can have it as a record within your stream. That’s way too many chocolates though, right?
Okay, okay, let’s talk tech then. So, if you haven’t been living under a rock for past 5 years, there’s a chance you already know about Kafka. Here’s what Kafka looks like:

Sorry, I meant this one:
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Yeah, that’s just how folks who maintain https://kafka.apache.org/ feel about Kafka. Now, do you agree that my chocolate analogy was much better?
The Setup
Now when I talk about Kafka, what I’m mostly referring to is Apache Kafka. The reason why I specifically wrote this is because there are 2 versions of Kafka which are extremely popular in the community, namely Apache Kafka and Confluent Kafka. I’ll not go into too much detail regarding differences between Apache Kafka and Confluent Kafka, but in a nutshell:
Apache Kafka is a message broker which is open source and provides high throughput and low latency. It can be used on its own.
Confluent Kafka, on the other hand, provides technologies that uses Apache Kafka as an underlying layer. Examples include: pre-built connectors and ksqlDB (something I’m particularly interested in reading more about these days, might end up writing another article about it, if the interest remains).
In the past, I’ve also worked with other message brokers like RabbitMQ and nsq. And even though all 3 have some differences, something they all agree on is to act as a tool to which one entity pushes something, and as a result, something happens.
With all this being said, let’s dive into how one can setup and use Kafka as a message broker for their backend/data engineering projects.
On a high level, there are 2 actors in every such act of sending and receiving data.
- Producer
- Consumer
A Producer is an application that writes or publishes messages/events on the Kafka topic. To be precise, it publishes them to a partition of the topic.
A Consumer, as the name suggests, will simply consume or read these messages/events from the Kafka topic. Depending on the number of consumers present in one consumer group, a consumer can read from 1 or multiple partitions which are part of the same topic.
If terms like partition, topic or consumer group are rather new to you as well, worry not. Let’s talk about them first.
And as Buzz Lightyear said,

The Build
Have you seen Inception?
If not, please stop reading right here. Go, watch it on streaming somewhere right away and then come back. I’m sure Kafka can wait, but Inception certainly can’t.
Here, you’re welcome.
So, assuming you have, you must be aware of the plot which revolves around the concept of having a dream within another dream. Let’s use that to explain Kafka concepts in a bit detail before we touch the code to do it on our own. And let’s do it in reverse for better understanding, i.e. we’ll visit the deepest layer first, then the one on top of it, then the one on top of it and so on.
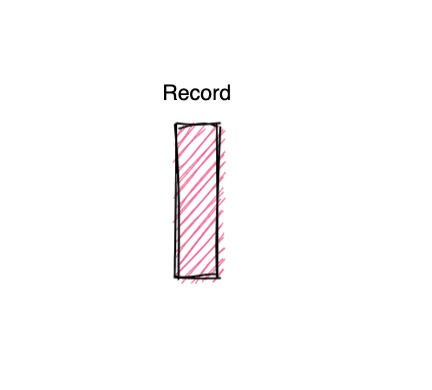
- Record
A record for Kafka is a small piece of data. It is an array of bytes that’s sent by the producer, and after passing through a Kafka topic, received by consumer(s).
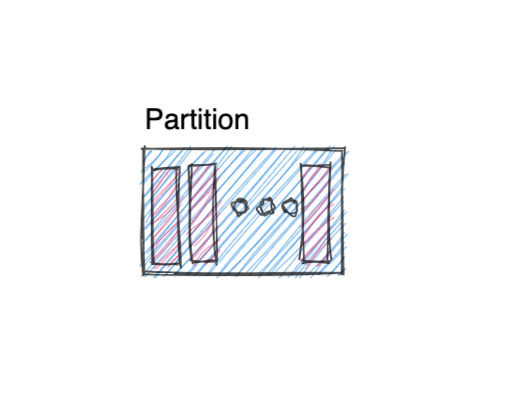
2. Partition
While using a partitioned topic, a producer can choose which partition to push messages to.
So a topic can be broken down into multiple partitions and different producers can choose whether they want to push to partition 0, partition 1 or partition n. This also allows us to parallelize a topic by splitting the data in a particular topic across multiple brokers.
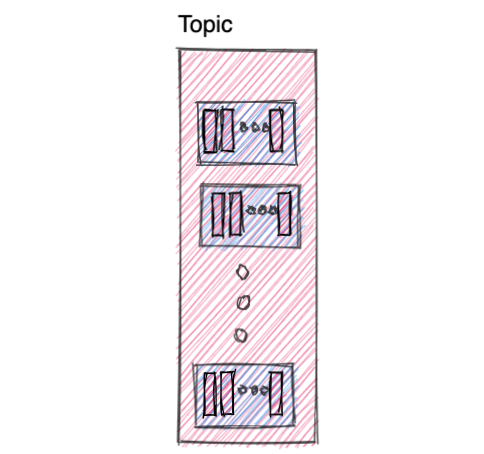
3. Topic
A topic is a log of events (yup, that’s it).
In a bit-less boring language, it is a unit of organization, used to hold messages/records of same type. A topic can have multiple partitions, as discussed above.
4. Broker
Finally, A broker is a server that consumers and producers interact with, at least on a high level. So, every application that wants to either produce or consume to a topic, must first connect to the broker(s) which store it.
A Kafka which consists of multiple partitions, is distributed among several brokers.
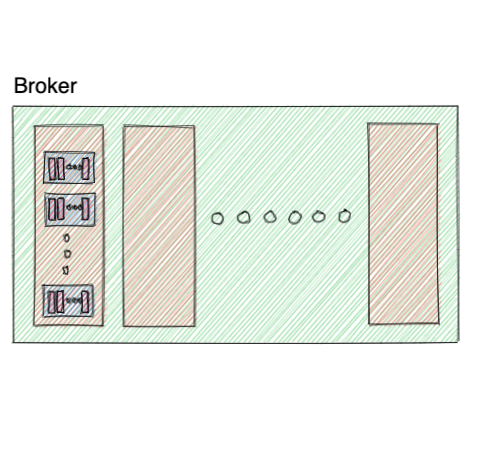
5. Cluster
A cluster, as the picture below suggests, is made up of several Kafka brokers. Here, every broker will have a unique ID.
A major objective of having a Kafka cluster, is to distribute workload among replicas and partitions.
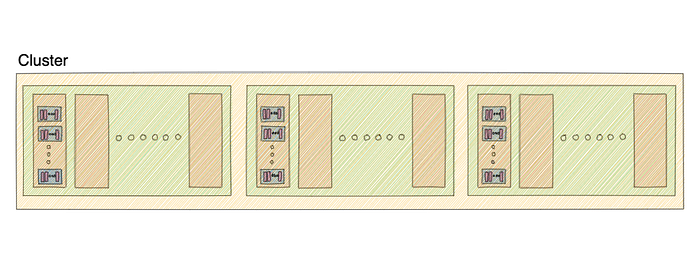
That was a lot of copy-pasting for me from excelidraw 😫, so I hope it was worth it for you.
Steps to install and run Kafka on LINUX systems
Before doing anything, you might wanna check that the JRE is installed. If not, you can do that by using the following commands:
sudo apt-get update
sudo apt-get install default-jreWith the above done successfully, you can verify the JAVA version to ensure everything looks good.

Next, we download the latest version of Apache Kafka as a tar file. You can find the downloads page here.
You can wget the file and then extract the same file in a folder.
wget https://dlcdn.apache.org/kafka/3.2.1/kafka_2.13-3.2.1.tgz
tar -xzf kafka_2.13-3.2.1.tgz
cd kafka_2.13-3.2.1With all being done, your terminal should look something like this.

Now, to start Kafka, first we need to start Zookeeper. If this is the first time you’re hearing about something called Zookeeper (which is quite a fancy name if you ask me, and you can thank Yahoo! for it), I can enlighten you with a brief about it.
ZooKeeper is essentially a service for distributed systems offering a hierarchical key-value store, which is used to provide a distributed configuration service, synchronisation service, and naming registry for large distributed systems.
source: Wikipedia
When working with Kafka, it basically tracks the status of several nodes that are part of a Kafka cluster, and along with it, a list of all the topics and messages within them.
The command to start zookeeper is:
bin/zookeeper-server-start.sh config/zookeeper.propertiesIn parallel, start another terminal or another tab in the same terminal, to start the Kafka cluster using the following command:
bin/kafka-server-start.sh config/server.propertiesNow, what I usually do, in such “setup-speedruns”, is to pray for a second. I pray and hope that the tutorial I’m following works. I’d suggest you do the same.
So far, this is what we’ve done:
- Install JRE
- Download and extract Kafka
- Open 2 terminals
- Run Zookeeper in one and Kafka in another
If you did all 4 in that same sequence, you should be able to see the following as output:
And when this happens, that means it is..

A few important notes before moving forward,
- The tutorial uses Kafka 2.3–3.2.1 which requires Zookeeper. Soon, as the documentation suggests, zookeeper will no longer be required by Apache Kafka.
- In both the commands mentioned above, a .properties file is used. I’d suggest you open them and go through their content. It is not mandatory, but doing this will give you some insight into what properties play a pivotal role in communication between Kafka and Zookeeper.
- Having a zookeeper maintaining node and connection statuses, is truly magical. In fact, Once we’ve setup everything using Kafka, I’ll show you how effective Zookeeper is at its job.
The Payoff
Next, we start 2 more terminals (I knowww, too many terminals).
With Kafka and Zookeeper running, we’re all set to finish this. Lets gooo..
Using Kafka to send and receive messages via a topic
- Create a topic (getting back to my chocolate analogy). You can use the following command to do that:
bin/kafka-topics.sh \
--create \
--topic all-chocolates-that-we-buy \
--bootstrap-server localhost:9092If the topic gets successfully created, you should get something similar to the screenshot below. Also, it means everything is working fine.

2. Start a consumer, using the command given below:
bin/kafka-console-consumer.sh
--bootstrap-server localhost:9092
--topic all-chocolates-that-we-buy3. In parallel, on the 4th terminal, we should also start a producer so that we can push some messages to the topic and see if they’re being actively picked up by the consumer.
bin/kafka-console-producer.sh
--bootstrap-server localhost:9092
--topic all-chocolates-that-we-buyNow’s THE BIG MOMENT (so big that I actually put it in caps), that we’ve been waiting for. Its time to use our Kafka stream to send and receive messages via a topic.
With the terminal having a producer connected to my favorite topic “all-chocolates-that-we-buy”, I’ve pushed the following 3 messages:
>cadbury dairy milk,101,20 INR
>perk,102,10 INR
>kit-kat,103,30 INRAnd since, no error popped up. I’m sure the consumer got them all.
See.

And tada!!, now you know about all the chocolates that I bought in past 3 days, not for me though.
I hope the article (and all the references) were worth the time.
Some important properties I want to mention before closing this article:
- Replication Factor
- Partitions
- Consumer Group
I’ll probably do another example using these in the next article. But meanwhile, if you want, you can read up on these as they play quite an important role while creating and using topics.

In Part-2, We’ll see how to do the same using Python 🐍, docker-compose 💻 and confluent-kafka, which is one of the several popular packages used for this purpose.
Click here for Part-2 when you’re done with this one.
Until then, you can look at
“An astronaut, riding a horse, in a photo-realistic style.”
Which looks something like this:

And since, I’m watching Better Call Saul these days, which is in its final season, here’s a song recommendation:
Something Stupid by Lola Marsh.
If you like my work, which is a bit rare, since its a mix-and-match of engineering, cinema and meme references. But in case you do, feel free to follow me. I’ll probably keep writing like this only.
Alright, till next time (hoping I write again soon),
À Bientôt
