Kafka with Python: Part 2 [3AE]
Streaming with some more pythonic swag
So, as of now, there are 16 views on the Part 1 of this, which is 6 more than what I had initially expected. As a result, here I am, attempting to finish what I started.
You better,

As usual, before we dive into the world of infinite chocolates and obsess over when they’re bought, let’s recap what we did the last time I was writing about this. We tried to answer questions like:
Question 01: What is Kafka, what are its popular variants and what are the alternatives present in the market, doing similar things?
Question 02: What are some of the important components in setting up and using a Kafka cluster?
Question 03: How to install and run Kafka on a Linux based system?
Question 04: How to create a topic, push and consume a message within Kafka?
Question 05: How many parts will there be in this series?, and the answer to this one, only 2.
Up next, we’ll try to do the following:
- Setting up a python project which using a 3rd party library to connect to the Kafka topic, to produce and consume message.
- Writing a wrapper class, to smoothen (is smoothen not a real word?) out some of the edges of configuring producers and consumers.
- Finally see how a Zookeeper+Kafka combination ensures that no message is lost in the conversation.
I know that was a lot of text to process in 1 go, but what can I do? That’s what happens when you promise yourself to write 5 articles by the end of the year and then spend 1 month just in thinking:

Alright, here we go:
The Setup
Starting right where we left off, let’s power up 🚀 both Zookeeper 🐼 and Kafka on 2 different terminals, and create a topic “timeless-cinema” (Read my bio to know why I chose this topic).

Important to note here, is the property partition while creating the topic. That’s the magic ingredient to make a distributed system scalable, as you can have multiple applications, producing and consuming from different partitions of the same topic. Hence, on increasing the load, we can just add more clients to handle it all without breaking a sweat.
Now, let’s open my 2nd favorite IDE (PyCharm 🐍 will always be the king), i.e. VS Code, and start writing some code:
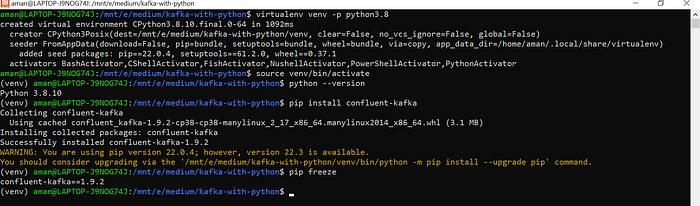
Create a new folder, and like every good developer out there, let’s first create a virtual environment, so that we don’t mess up any other project’s dependencies.

After that, let’s install the package that we’ll be working with for the rest of our tutorial — confluent-kafka. There are some alternatives to this library like: kafka-python and pykafka, and I’m certain that they all operate almost the same way. However I found the documentation of confluent-kafka to be very intuitive and easy to use (personal opinion, yours might differ).
mkdir kafka-with-python
cd kafka-with-python
virtualenv venv -p python3.8
pip install confluent-kafka
pip freezeThe commands above should give you something like this (ignore the warning, just like all the other ones):
Next, let’s take a look into the folder structure within VSCode before we start writing 🐍 python:
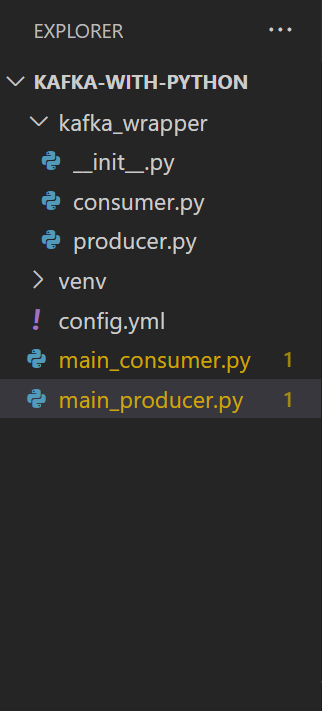
A bit about each file (so that the gibberish afterwards, makes some sense):
kafka_wrapper/consumer.py : contains wrapper class definition to connect to the topic as a consumer
kafka_wrapper/producer.py : contains wrapper class definition to connect to a topic as a producer
kafka_wrapper/__init__.py : __init__ file to simplify package imports
config.yml : contains all the configuration about the kafka topic
main_producer.py : to execute all the package code to produce messages
main_consumer.py : to execute all the package code to consume messages
The Build
Just to touch up again on what exactly is a producer and a consumer, let me just copy-paste from the previous post:
A Producer is an application that writes or publishes messages/events on the Kafka topic. To be precise, it publishes them to a partition of the topic.
A Consumer, as the name suggests, will simply consume or read these messages/events from the Kafka topic. Depending on the number of consumers present in one consumer group, a consumer can read from 1 or multiple partitions which are part of the same topic.
WARNING! VERY COMPLICATED CODE BLOCKS AHEAD
Lets start with __init__()method of our producer, and then I’ll explain a bit about each argument passed and initialized:
1. topic : The Kafka topic you’ll like to attempt connecting to in order to push messages.
2. partition : As explained previously, every topic has multiple partitions. While pushing messages, you must first determine the partition you wish to send messages to.
3. producer : Producer() class instance from confluent-kafka.
4. on_delivery : Every time the producer pushes a message successfully, what method should execute. (There’s a catch to it though, as you’ll see later)
5. enable_flush : flush() is a method that waits for all messages in the Producer queue to be delivered. We use enable_flush as a flag to trigger this method manually. (head over here to read some interesting arguments about it)
Up next, let’s define a default on_delivery() method to run whenever we push a message. This will come in handy if you don’t override the property while initializing:
Finally, let’s write the method that will use all the code above:
Combine this all and you have your class ready for kafka_wrapper/producer.py :
Now, since you’ve done so much work in 1 go, A funny cat gif from the internet for you (hoping you’re a cat person, like me)

Enough fun, let’s speed up and repeat the whole process for our consumer as well. First, the __init__() method which again takes a series of arguments, which I’ve explained right below the snippet:
- time_out : Maximum time to block waiting for message, event or callback. If not set, is considered infinite.
- on_assign_ref: Function to call every time the consumer instance gets assigned some partitions.
- on_revoke_ref: Function to call every time the consumer instance is revoked from some partitions.
- topic : Topic(s) the consumer will be consuming from
- consumer :
Consumer()class instance from confluent-kafka
As usual, default methods for _on_assignment and _on_revoke to use if not overridden while initializing new KafkaConsumer() objects.
Once we have all the values we need, the next step is to connect to the topic using the configuration. The important thing here to note is that just connecting isn’t enough, as later, we’ll use this connection to poll/listen for incoming messages.
Finally, let’s finish this by combining everything from above. On top of it, a couple more methods, namely, poll() and close() . The first one helps us in listening for incoming messages, while the second one just closes the connection created before.
Phewww! That was intense, righttttt, right? Only getting started.
Let’s create the configuration to use all the complex stuff we wrote above. That being said,
NO MORE COMPLICATED CODE BLOCKS AHEAD
For my next trick, we’ll need a new package (because I’m too lazy to write something from scratch to read yml files)
pip install pyyamlThe config.yml for our use-case looks something like this:
Here, 2 things to consider:
- We need the property
groupto determine the consumer group for our consumers. A consumer group is a set of consumers which cooperate to consume data from the same topic. This helps as when members of same group either arrive or leave, the partitions can be reassigned automatically. - We need the property
partitionfor the producer to identify the specific partition of the topic to produce the message to. The producer then, will send a produce request to the leader of that partition.
The Payoff
That’s it.

Following (main_producer.py) will help you to push a message to the topic created initially (i.e., timeless-cinema):
Running the same on shell, you should be able to see a confirmation message (thanks to our callback message from the class):

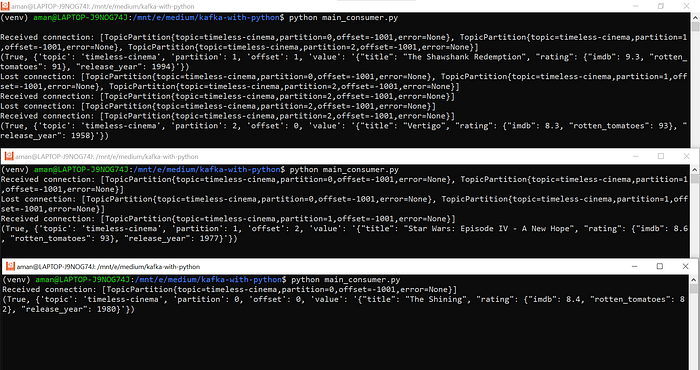
Now, lets do one thing, instead of 1 consumer, lets have 3 of them (why 3? you wonder).
What do you think will happen if I start the first one?
What do you think will happen when I start the second one?
What do you think will happen when I start the third one?

I’m gonna let the logs do the talking
Following would be the code for my main_consumer.py, which is essentially a file which we will run thrice on 3 different terminals.

Sorrrryyyy!!, but if I was doing it with PyCharm, it’d have been a lot easier 😧.
Again, another property to note here is auto.offset.reset, which is useful for deciding, what to do when there’s no initial offset in Kafka. In our case, earliest tells Kafka to let us read everything from the beginning.
Okay, answering my first question:

So, we have our 1 consumer, managing all 3 partitions of timeless-cinema
Answering my 2nd question, after starting another consumer on a different terminal. Note how the first consumer reacts to the 2nd one coming online
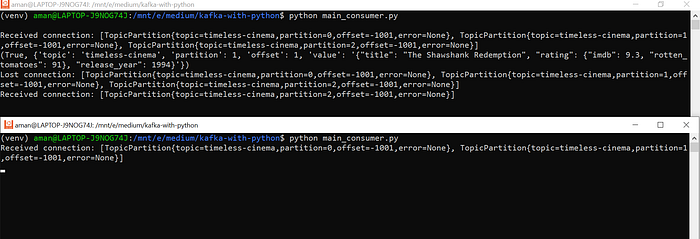
You see?
That’s the magic of having Zookeeper, making it all possible. In case you missed it, let me try it again, by starting a 3rd consumer and answering my 3rd question:
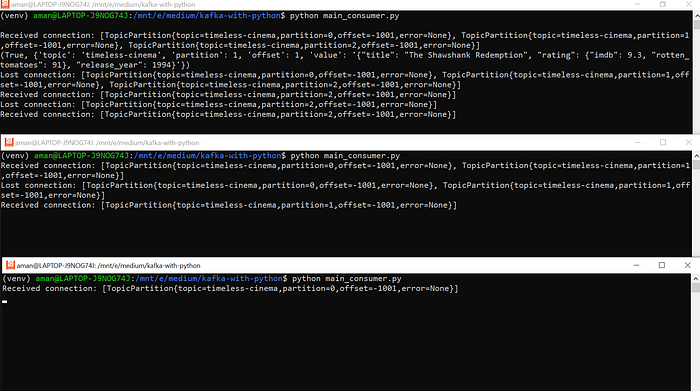
Now you get it?
Alright, let me break it down (the best I can). As soon as new Kafka consumer comes into the picture, the existing Kafka consumers talk to each other and share the load of partitions.
Initially this is how it was:
Consumer 0: Partition 0, Partition 1, Partition 2
As soon as consumer 2 comes online, this is how it becomes:
Consumer 0: Partition 2
Consumer 1: Partition 0, Partition 1
Again when consumer number 3 comes up, this is how it gets redistributed:
Consumer 0: Partition 2
Consumer 1: Partition 1
Consumer 2: Partition 0
So, for each of the partition we have 1 consumer, actively consuming messages coming to that partition. Hence, making Kafka the god of asynchronous messaging systems.

Trust me, when I realized this myself, I felt like discovering something godly, but that’s just brilliant engineering and a thought process that made it possible.
Let me push some more messages, talking about awesome cinema like —
Before producing each message, I can simply update the config.yml with new partition number and the consumer responsible for consuming that partition will consume it, giving me something like:
And that, my friend is how you do Kafka, with some pythonic swag.
Before signing off, I’d request you to take a look at all the possible configuration for Kafka topics, producers and consumers. Find them here.
I recently watched Metal Lords, and it had all the metal that I grew up listening to, from Judas Priest to Black Sabbath. If something like that interests you, make sure you check it out.
And of course, if you’re traveling to Delhi by any chance, after long time (as I was a couple weeks back), you have to visit:

That’s my 1st out of 5 articles for the year (yes, still gonna fail), 4 more to go before year end :)
fin
