Data Quality, Orchestrated — Part I [3AE]
If I could name the 2nd most important thing, everyone in the org. cares about, its the quality of the data (1st still being the paycheck). While working with datasets of TBs and PBs, it becomes second nature to care about what data is coming in the system and how good is that (the ‘good’ is subjective here, personally I had no problems with integers coming as strings).
Over the years, I’ve spent my fair share of time in building, testing and writing data quality tools. Few major players that always come up in every discussion around data quality, would be AWS Deequ, great-expectations and Soda Core.
The Setup
For this one, let’s talk about great expectations, and more importantly how much people have expected in the past. So much that there’s:
A novel by this name.
A documentary by this name.
A show by this name.
An album by this name (many actually).
And a python library by this name (one we’re here for).

great-expectations (the library) has terminology equivalent to number of main characters in Attack on Titan (Yes, I’m binging it this month).
That being said, great expectations deals with this by maintaining a plethora of documentation on everything. Some important, good to know terms would be:
Since gx (import great_expectations as gx) has done such a great job in defining these, I’d suggest you read their content over my childish definitions to understand why it exists in the first place.
A very well explained video, which is more than enough to get started with this would be:
With all this said/read/watched, let’s see what’s on the main menu today. The article is split in 2 parts:
Part 1, one you’re reading right now will deal with initializing the library, creating an expectation suite and validating some data with it.
Part 2, will be about integrating the same with an orchestrator like Airflow in your next data pipeline.
IMPORTANT
Following are the versions I have at the time of writing this:
Python 3.8.10
great-expectations 0.17.23
I can’t stress it enough to use the exact same versions for similar results. A major con while using such a heavily maintained library is that a lot of functions go deprecated or completely removed in every 2nd release.
Alright, buckle up!

The Build
With an intent to write and run things in an isolated environment, lets start by setting up a virtual environment:
mkdir great-expectations-demo
cd great-expectations-demo
virtualenv venv -p python3.8
source venv/bin/activate
pip install great-expectations==0.17.23Create sufficient files for the demo, so that the tree command gives output like the following:

The first thing to do, is to initialize a great expectations environment, using the following command:
great-expectations initThe tree command should give something like the following:
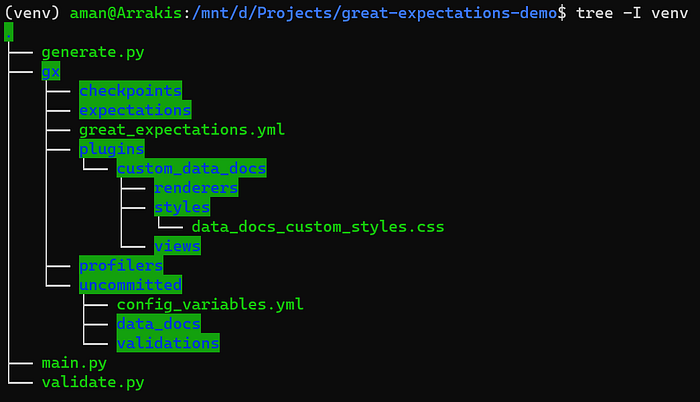
A lot of what the command creates might not be in the scope of the article, but its important for exploring some other features of the library. Some boilerplate code (main.py) which looks like this:
import json
from typing import List
import great_expectations as gx
from great_expectations.core.expectation_configuration import ExpectationConfiguration
from great_expectations.data_context.types.resource_identifiers import ExpectationSuiteIdentifier
from great_expectations.core.expectation_validation_result import ExpectationSuiteValidationResult
class ExpectationConfig:
def __init__(self, path) -> None:
pass
def get_expectations_list(self) -> List[ExpectationConfiguration]:
pass
class GreatExpectationsManager:
def __init__(self, suite_name) -> None:
pass
def generate_suite(self, expectations_list) -> None:
pass
def generate_and_open_data_docs(self) -> None
pass
def validate(self) -> ExpectationSuiteValidationResult:
passTo keep things dynamic, easily adaptable and changeable in future, I’ll keep most of the configuration bit for the expectation suite in a .json file. This will help us to easily mimic the functionality and extend it as per the need in future.
Let’s create one file named expectations.json in the same directory:
[
{
"name": "expect_column_values_to_not_be_null",
"column": "pickup_datetime",
"extra_args": {
"result_format": "BASIC"
}
},
{
"name": "expect_column_values_to_be_between",
"column": "trip_distance",
"extra_args": {
"min_value": 0,
"max_value": null,
"result_format": "BASIC"
}
},
{
"name": "expect_column_values_to_be_in_set",
"column": "payment_type",
"extra_args": {
"value_set": [1, 2, 3],
"result_format": "BASIC"
}
}
]We can populate the following code in ExpectationConfig to read the file created above, create a list of expectations and pass it forward while building the suite.
class ExpectationConfig:
def __init__(self, path) -> None:
with open(path, "r") as file:
self.config = json.load(file)
def get_expectations_list(self) -> List[ExpectationConfiguration]:
expec_list = []
for item in self.config:
expec_list.append(ExpectationConfiguration(**{
"expectation_type": item["name"],
"kwargs": {
"column": item["column"],
**item["extra_args"]
}
}))
return expec_listSimilarly, lets populate the class GreatExpectationsManager, which should do the following:
- Initiate a gx context in the environment
- Create expectation suite and save it in the gx context.
- (Optional) Create and open data docs (for validating whatever we’ve done so far is actually correct)
- Have functionality to validate a dataset.
class GreatExpectationsManager:
def __init__(self, suite_name) -> None:
self.context = gx.get_context()
self.suite_name = suite_name
def generate_suite(self, expectations_list) -> None:
self.suite = self.context.create_expectation_suite(
expectation_suite_name=self.suite_name,
overwrite_existing=True
)
for expectation_conf in expectations_list:
self.suite.add_expectation(expectation_configuration=expectation_conf)
save_path = self.context.save_expectation_suite(expectation_suite=self.suite)
save_path = save_path.replace("\\", "/")
print("Suite created successfully as:",save_path)
def generate_and_open_data_docs(self) -> None:
suite_identifier = ExpectationSuiteIdentifier(expectation_suite_name=self.suite_name)
self.context.build_data_docs(resource_identifiers=[suite_identifier])
self.context.open_data_docs(resource_identifier=suite_identifier)
def validate(self, input_dataset_path) -> ExpectationSuiteValidationResult:
suite = self.context.get_expectation_suite(self.suite_name)
validator = self.context.sources.pandas_default.read_csv(input_dataset_path)
validation_result = validator.validate(expectation_suite=suite)
return validation_resultThe Payoff
Alright, time to test whether all the time spent so far actually helps the cause or not. First, generate.py, which should create the suite:
from main import ExpectationConfig, GreatExpectationsManager
config_object = ExpectationConfig("./expectations.json")
expectations_list = config_object.get_expectations_list()
ge_manager = GreatExpectationsManager('my_suite_v1')
ge_manager.generate_suite(expectations_list)
ge_manager.generate_and_open_data_docs()Running the above will give an output like the following:
Suite created successfully as: .../great-expectations-demo/gx/expectations/my_suite_v1.jsonAdditionally, the best way to see whether everything worked out well is to do it via the data-docs. The last function call will open the same in the browser, which looks something like this:
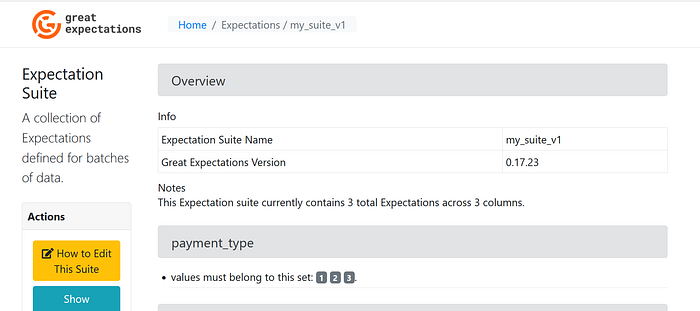
Let’s summarize what have we done so far:
We initialized a great expectations context.
We created a .json file which contains all expectations for our suite
We created and saved an expectations suite name ‘my_suite_v1’
Up next, let’s use the same file (my_suite_v1.json), to validate some data.
For this, let’s setup a data-source, which has data matching the expectation suite we built before. The following command should help:
wget -O data.csv "https://raw.githubusercontent.com/great-expectations/gx_tutorials/main/data/yellow_tripdata_sample_2019-01.csv"Finally, the following code for validate.py:
from main import GreatExpectationsManager
suite_name = "my_suite_v1"
input_data_path = "data.csv"
ge_manager = GreatExpectationsManager(suite_name)
validation_result = ge_manager.validate(input_data_path)
print(validation_result)If today is a good day for you, and you’ve shown 0 creativity in following the process so far, you should get something which looks like:
Calculating Metrics: 100%|████████████████████████████████████████████████████████████| 16/16 [00:00<00:00, 552.37it/s]
{
"success": false,
"results": [
{
"success": true,
"expectation_config": {
"expectation_type": "expect_column_values_to_not_be_null",
"kwargs": {
"column": "pickup_datetime",
"result_format": "BASIC",
"batch_id": "default_pandas_datasource-#ephemeral_pandas_asset"
},
"meta": {}
},
"result": {
"element_count": 10000,
"unexpected_count": 0,
"unexpected_percent": 0.0,
"partial_unexpected_list": []
# and so onAnd the moment we were all waiting for:

Most of the design followed in the article is easily replaceable, so tomorrow if we have to update a single functionality or even the whole library, doing it shouldn’t be a very big pain.
In recent months, other than preparing for a job change (which deserves a separate post in itself), I’ve:
Tried to finish podcasts by Nikhil Kamath, and rigorously try noting down important things (as if I’ll ever read them again)
Made an account on letterboxd, to create a catalog of 400+ yet to watch films.
Watched highly acclaimed The OA, and then watch 5 different theories around it.
Also, Across The Spider-verse, which was certainly a miss, and should have been experienced in the theater.
P.S, Spotify Wrapped says I was in the top 5% listeners worldwide (not sure if I should be happy or depressed about it)

Until the next one.
fin

![Apache Arrow, making Spark even faster [3AE]](https://miro.medium.com/v2/resize:fit:679/1*7ukrOexLk8MLCRxr-vBL4w.png)
![Spark Listener, and how to setup yours [3AE]](https://miro.medium.com/v2/resize:fit:679/0*NC0Eu9l_5fVOfo9T.jpg)
![Kafka with Python: Part 2 [3AE]](https://miro.medium.com/v2/resize:fit:679/0*5sqzUO2WkpU0L_-r.jpg)